1장 컴퓨터 구조 시작하기
개발할 때 문제없이 작동했던 코드가 실제 사용자들에게 선보이는 자리에서는 작동하지 않는 상황은 비일비재합니다. 이 경우 분명 코드상의 문법적인 우류만이 원인은 아닐 겁니다. 프로그래밍 언어의 문법만 알고 있는 살마에게 컴퓨터 코드를 입력하면 어찌어찌 알아서 결과물을 툭 내놓는 '미지의 대생'일 테니까요. 결국 이들은 컴퓨터라는 기계에 코드를 입력만 할 수 있을 뿐 그 이상을 하기는 어렵습니다.
하지만 컴퓨터 구조를 이해하고 있으면 문제 상황을 빠르게 진단할 수 있고, 문제 해결의 실마리를 다양하게 찾을 수 있습니다. 컴퓨터 내부를 거리낌 없이 들여다보며 더 좋은 해결책을 고민할 겁니다. 왜냐하면 이런 사고가 가능한 이들에게 컴퓨터란 '미지의 대상'이 아닌 '분석의 대상'일 테니까요.
이런 상황은 다른 누군가가 대신 해결해 주지 않습니다. 여러분이 개발한 프로그램이 어떤 환경에서 어떻게 작동하는지 여러분이 가장 잘 이해하고 있어야하고, 프로그램을 위한 최적의 컴퓨터 환경을 스스로 판단할 수 있어야합니다.
예를 들어 개발한 웹사이트가 유명해졌다고 가정해봅시다. 매일 새로운 회원 100명이 가입하고, 매일 새로운 글이 100개씩 생성되고 있다고 해봅시다. 이 웹사이트에 가입한 회원들의 정보, 그리고 각 회원이 남긴 게시글과 댓글은 어딘가에 저장되어 있어야겠죠? 다시말해서 저장 장치가 필요합니다. 어떤 저장장치가 필요할까요? 그리고 어느 정도의 용량을 갖춰야할까요? 이런 상황 또한 실력 있는 개발자라면 스스로 판단할 수 있어야합니다. 앞에서 제시한 두가지 상황으로 대표되는 성능, 용량, 비용 문제는 프로그래밍 언어의 문법만 알아서는 해결하기 어렵습니다. 혼자만 사용하는 프로그램을 만들 때는 이러한 문제를 생각조차 해본적이 없을 수도 있습니다. 하지만 사용자가 많은 프로그램은 필연적으로 성능, 용량, 비용이 고려됩니다. 그래서 컴퓨터 구조를 아는 것이 중요합니다.
우리가 알아야할 컴퓨터 구조 지식은 크게 두가지 입니다.

먼저 컴퓨터가 무엇을 이해하는지 알아야합니다.
컴퓨터는 0과 1로 표현된 정보만을 이해합니다. 이렇게 0과 1로 표현된 정보에는 크게 두가지 종류가 있는데, 바로 데이터와 명령어입니다. 컴퓨터가 이해하는 숫자, 문자, 이미지, 동영상과 같은 정적인 정보를 데이터라고 합니다. 컴퓨터와 주고받는 정보나 컴퓨터에 저장된 정보를 가리킬 때 편하게 데이터라 통칭하기도 하지요.
컴퓨터를 한마디로 정의하자면 "명령어를 처리하는 기계"라고 할 수 있습니다.
컴퓨터가 이해하는 정보에는 데이터와 명령어가 있다고 했지만, 이 둘 중 컴퓨터를 실질적으로 작동시키는 더 중요한 정보는 명령어입니다. 데이터는 명령어 없이는 아무것도 할 수 없는 정보 덩어리일 뿐이지만, 명령어는 데이터를 움직이고 컴퓨터를 작동시키는 정보이기 때문입니다.
명령어는 컴퓨터를 작동시키기 위해 존재하는 정보이고, 데이터는 명령어를 위해 존재하는 일종의 재료입니다. 이런점에서 컴퓨터 프로그램은 명령어들의 모음으로 정의되기도 합니다. 그래서 명령어는 컴퓨터 구조를 학습하는데 있어 데이터보다 저 중요한 개념이라고 할 수 있습니다.
컴퓨터는 외관과 용도를 막론하고 컴퓨터를 이루는 핵심 부품은 크게 다르지 않습니다. 컴퓨터의 핵심 부품은 중앙 처리장치, 주기억장치(이하 메모리), 보조 기억장치, 입출력 장치입니다. 이 네가지 부품의 역할만 이해하고 있어도 컴퓨터의 작동원리를 대부분 파악할 수 있습니다.
주기억장치에는 크게 RAM(Random Access Memory)과 ROM(Read Only Memory), 두가지가 있습니다. 메모리라는 용어는 보통 RAM을 지칭합니다. 컴퓨터의 작동 원리를 파악하기 위해 여러분이 알아야할 더 중요한 주기억장치는 RAM입니다. 따라서 특별한 언급이 없는 한 이 책에서 다루는 주 기억장치는 RAM이라고 해도 무방합니다.
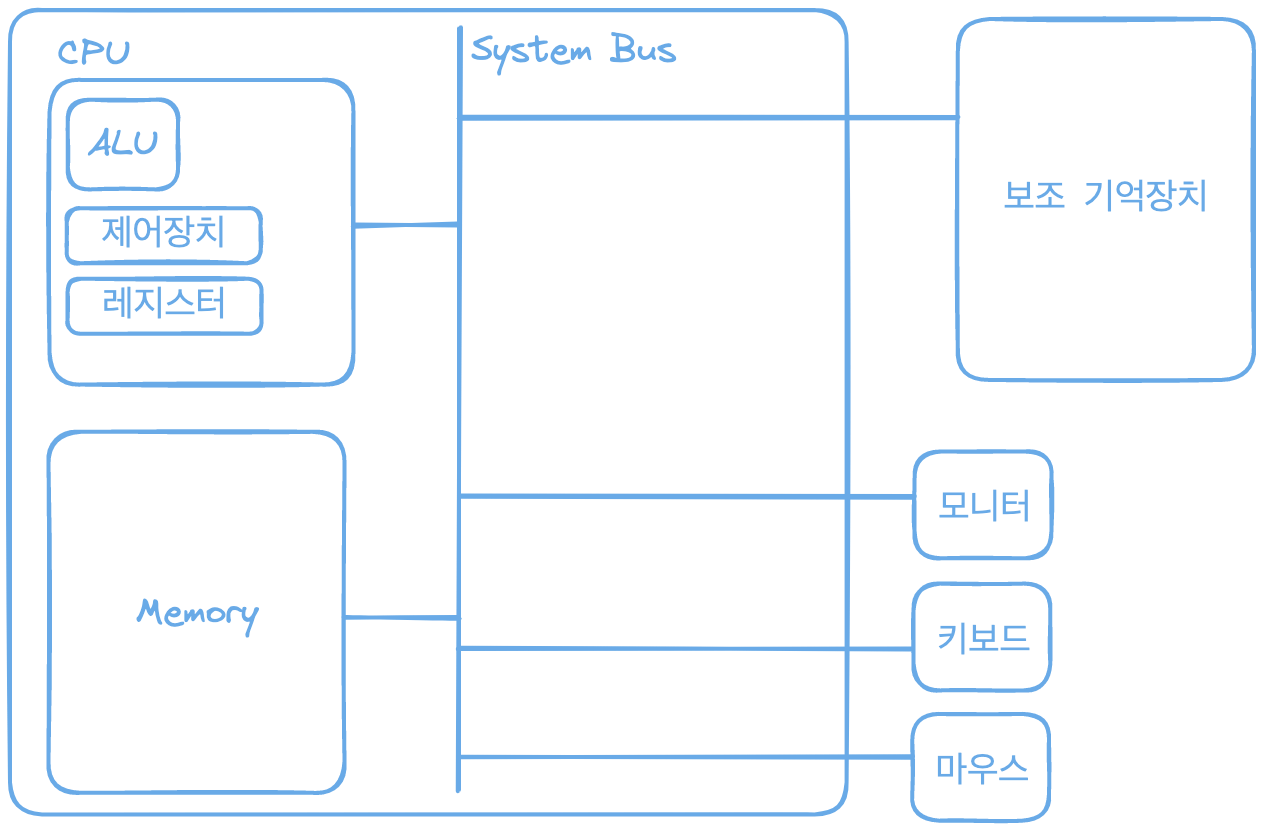
가장 큰 사각형은 메인보드이고 메인보드안에 시스템 버스가 있습니다. CPU내부에는 ALU(산술 논리 연산장치), 제어장치와 여러 레지스터들이 있습니다. CPU는 메인보드 내 시스템 버스와 연결되어 있습니다. 메모리는 메인 보드 내 시스템 버스와 연결되어 있습니다. 보조 기억 장치는 메인 보드 내 시스템 버스와 연결되어 있습니다. 모니터, 키보드, 마우스등은 메인보드 내 시스템 버스와 연결되어 있습니다. 이들을 입출력 장치라고 부릅니다.
메모리
컴퓨터가 이해하는 정보는 명령어와 데이터입니다. 메모리는 현재 실행되는 프로그램의 명령어와 데이터를 저장하는 부품입니다. 즉, 프로그램이 실행되려면 반드시 메모리에 저장되어 있어야합니다.
이 때 컴퓨터가 빠르게 작동하기 위해서는 메모리 속 명령어와 데이터가 중구난방으로 저장되어있으면 안됩니다. 저장된 명령어와 데이터의 위치는 정돈되어 있어야합니다. 그래서 메모리에는 저장된 값에 빠르고 효율적으로 접근하기 위해 주소(address)라는 개념이 사용됩니다.
CPU
CPU는 컴퓨터의 두뇌입니다. CPU는 메모리에 저장된 명령어를 읽어 들이고, 읽어 들인 명령어를 해석하고, 실행하는 부품입니다.
CPU의 내부 구성 요소중 중요한 세가지는 산술 논리 연산 장치(이하 ALU), 레지스터, 제어 장치(Control Unit)입니다.
ALU는 쉽게 말해 계산기 입니다. 계산만을 위해 존재하는 부품이죠. 컴퓨터 내부에서 수행되는 대부분의 계산은 ALU가 도맡아 해줍니다.
레지스터는 CPU 내부의 작은 임시 저장 장치입니다. 프로그램을 실행하는데 필요한 값들을 임시적으로 저장합니다. CPU안에는 여러개의 레지스터가 존재하고 각기 다른 이름과 역할을 가지고 있습니다.
제어장치는 제어 신호라는 전기 신호를 내보내고 명령어를 해석하는 장치입니다. 여기서 제어 신호란 컴퓨터 부품을 관리하고 작동시키기 위한 일종의 전기 신호입니다.
- CPU가 메모리에 저장된 값을 읽고 싶을 땐 메모리를 향해 메모리 읽기라는 제어 신호를 보낸다.
- CPU가 메모리에 어떤 값을 저장하고 싶을 땐 메모리를 향해 메모리 쓰기라는 제어 신호를 보낸다.
보조 기억 장치
앞서 메모리는 실행되는 프로그램의 명령어와 데이터를 저장한다고 했지만, 이 메모리는 두가지 치명적인 약점이 있습니다. 첫째는 가격이 비싸 저장 용량이 적다는 점이고, 둘째는 전원이 꺼지면 저장된 내용을 잃는다는 점입니다. 실행 중인 프로그램들은 메모리에 저장되는데 메모리는 전원이 꺼지면 저장된 내용이 날아가기 때문이다.
메모리보다 크기가 크고 전원이 꺼져도 저장된 내용을 잃지 않는 메모리를 보조할 저장장치가 필요한데 이를 보조 기억장치라고합니다.
하드디스크, SSD, USB 메모리, DVD, CD-ROM과 같은 저장 장치가 보조 기억 장치의 일종입니다.. 컴퓨터 전원이 꺼져도 컴퓨터에 파일이 남아 있었던 이유는 우리가 파일을 보조 기억장치에 저장했기 때문입니다. 메모리가 현재 실행되는 프로그램을 저장한다면, 보조 기억장치는 보관할 프로그램을 저장한다고 생각해도 좋습니다.
메인 보드와 시스템 버스
메인 보드는 마더 보드(mother board)라고도 부릅니다. 메인보드는 앞의 부품을 비롯한 여러 컴퓨터 부품을 부착할 수 있는 슬롯과 연결 단자가 존재합니다. 메인 보드에 연결된 부품들은 서로 정보를 주고 받을 수 있는데, 이는 메인보드 내부에 버스라는 통로가 있기 때문입니다. 컴퓨터 내부에는 다양한 종류의 통로, 즉 버스가 있습니다. 하지만 여러 버스 가운데 컴퓨터의 네가지 핵심 부품을 연결하는 가장 중요한 버스는 시스템 버스입니다.
시스템 버스는 주소버스, 데이터 버스, 제어 버스로 구성되어 있습니다. 주소 버스는 주소를 주고 받는 통로, 데이터 버슨느 명령어와 데이터를 주고받는 통로, 제어 버스는 제어 신호를 주고 받는 통로입니다. (CPU 구성요소중 하나인 제어장치는 제어 버스를 통해 제어 신호를 내보냅니다.)
CPU가 메모리 속 명령어를 읽어 들이기 위해 제어장치에서 '메모리 읽기'라는 신호를 내보낸다고 했습니다. 그런데 사실 CPU가 메모리를 읽을 때 제어신호만 내보내지 않습니다. 실제로 제어버스로 '메모리 읽기' 제어 신호를 보내고 주소 버스로 읽고자하는 주소를 내보냅니다. 그러면 메모리는 데이터 버스로 CPU가 요청한 주소에 있는 내용을 보냅니다. 그리고 메모리에 어떤 값을 저장할 때도 CPU는 데이터 버스를 통해 메모리에 저장할 값을, 주소 버스를 통해 저장할 주소를, 제어 버스를 통해 '메모리 쓰기' 제어 신호를 내보냅니다.
2장 데이터
0과 1을 나타내는 가장 작은 정보 단위를 비트라고 합니다. 우리가 실행하는 프로그램은 수십만 비트, 수백만 비트로 이루어져 있습니다. 바이트는 여덟 개의 비트를 묶은 단위로, 비트보다 한 단계 큰 단위입니다. 그럼 하나의 바이트가 표현할 수 있는 정보는 몇 개일까요? 1바이트는 8비트와 같으니 256개를 표현할 수 있겠죠. 바이트 또한 더 큰 단위로 묶을 수 있는데, 1바이트 1000개를 묶은 단위를 1킬로바이트라고 합니다. 그리고 1킬로바이트 1000개를 묶은 단위를 1메가 바이트, 1메가바이트 1000개를 묶은 단위를 1기가바이트, 1기가바이트 1000개를 묶은 단위를 1테라 바이트라고 합니다. 테라바이트보다 더 큰 단위도 있으나 여러분이 다루게 될 데이터의 크기는 최대 테라바이트까지인 경우가 많습니다.
중요한 정보 단위 중 워드라는 단위도 있습니다 .워드란 CPU가 한번에 처리할 수 있는 데이터 크기를 의미합니다. 만약 CPU가 한번에 16비트를 처리할 수 있다면 1워드는 16비트가 되고, 한번에 32비트를 처리할 수 있다면 1워드는 32비트가 되는 것이죠. 이렇게 정의된 워드의 절반 크기를 하프워드(half word), 1배 크기를 풀 워드(full word), 2배 크기를 더블 워드(double word)라고 부릅니다. 워드가 큰 CPU는 한 번에 처리할 수 있는데이터가 많습니다. 워드 크기는 CPU마다 다르지만, 현대 컴퓨터의 워드 크기는 대부분 32비트 또는 64비트입니다. 가령 인텔의 x86 CPU는 32비트 워드, x64 CPU는 64비트 워드입니다.
0과 1을 문자로 표현하는 방법
컴퓨터가 인식하고 표현할 수 있는 문자의 모음을 문자집합(character set)이라고 합니다. 컴퓨터는 문자 집합에 속해 있는 문자를 이해할 수 있고, 반대로 문자 집합에 속해있지 않은 문자는 이해할 수 없습니다. 예를 들어 문자 집합이 {a, b, c, d, e} 인 경우 컴퓨터는 이 다섯 개의 문자는 이해할 수 있고, f나 g같은 문자는 이해하지 못합니다.
문자 집합에 속한 문자라고 해서 컴퓨터가 그대로 이해할 수 있는 건 아닙니다. 문자를 0과 1로 변환해야 비로소 컴퓨터가 이해할 수 있습니다. 이 변환 과정을 문자 인코딩(chracter encoding)이라 하고 인코딩 후 0과 1로 이루어진 결과값이 문자 코드가 됩니다. 같은 문자 집합에 대해서도 다양한 인코딩 방법이 있을 수 있습니다. 인코딩의 반대과정, 즉 0과 1로 이루어진 문자 코드를 사람이 이해할 수 있는 문자로 변환하는 과정은 문자 디코딩(chracter decoding)이라고 합니다.
정리하면 컴퓨터가 인식할 수 있는 문자들의 모음은 문자 집합, 이 문자들을 컴퓨터가 이해할 수 있는 0과 1로 변환하는 과정을 인코딩, 반대로 0과 1로 표현된 문자 코드를 사람이 읽을 수 있는 문자로 변환하는 과정을 디코딩이라고 합니다.
한글 인코딩에는 두가지 방식, 완성형(한글 완성형 인코딩)과 조합형(한글 조합형 인코딩)이 존재합니다. 완성형 인코딩 방식은 초성, 중성, 종성의 조합으로 이루어진 완성된 하나의 글자에 고유한 코드를 붙여 인코딩하는 방식입니다. 예를 들어 '가'는 1, '나'는 2, '다'는 3, 이런식으로 인코딩하는 방식이죠.
반면 조합형 인코딩 방식은 초성을 위한 비트열, 중성을 위한 비트열, 종성을 위한 비트열을 할당하여 그것들의 조합으로 하나의 글자 코드를 완성하는 인코딩 방식입니다. 다시 말해 초성, 중성, 종성에 해당하는 코드를 합하여 하나의 글자 코드를 만드는 인코딩 방식이죠.
EUC-KR은 KS X 1001, KS X 1003이라는 문자 집합을 기반으로 하는 대표적인 완성형 인코딩 방식입니다. 즉, EUC-KR 인코딩은 초성, 중성, 종성이 모두 결합된 한글에 대해 2바이트 크기의 코드를 부여합니다.
EUC-KR로 인코딩된 한글 한 글자를 표현하려면 16비트가 필요합니다. 그리고 16비트는 네자리 십육진수로 표현할 수 있습니다. 즉 EUC-KR로 인코딩된 한글은 네자리 십육진수로 나타낼 수 있습니다.
EUC-KR 인코딩 방식으로 총 2350개 정도의 한글 단어를 표현할 수 있습니다. 아스키 코드보다 표현할 수 있는 문자가 많아졌지만, 사실 이는 모든 한글 조합을 표현할 수 있을 정도로 많은 양은 아닙니다. 그래서 문자 집합에 정의되지 않은 '쀍', '쀓', '믜' 같은 글자는 EUC-KR로 표현할 수 없습니다. 모든 한글을 표현할 수 없다는 사실은 때때로 크고 작은 문제를 유발합니다. EUC-KR 인코딩을 사용하는 웹사이트의 한글이 깨진다든지, EUC-KR 방식으로는 표현할 수 없는 이름으로 인해 은행, 학교 등에서 피해를 받는 사람이 생겨나기도 했습니다.
이런 문제를 조금이나마 해결하기 위해 등장한 것이 마이크로소프트의 CP949(code page 949)입니다. CP949는 EUC-KR의 확장된 버전으로 EUC-KR로는 표현할 수 없는 다양한 문자를 표현할 수 있습니다. 다만 이마저도 한글 전체를 표현하기에 넉넉한 양은 아닙니다.
유니코드와 UTF-8
EUC-KR 인코딩 덕분에 한국어를 코드로 표현할 수 있게 되었습니다 .하지만 모든 한글을 표현할 수 없다는 한계가 있었죠. 더욱이 이렇게 언어별로 인코딩을 나라마다 해야 한다면 다국어를 지원하는 프로그램을 만들 때 각 나라 언어의 인코딩을 모두 알아야하는 번거로움이 있습니다. 예를 들어 한국어, 영어, 일본어, 중국어, 독일어를 지원하는 웹 사이트가 있다면 이 웹사이트는 다섯개의 언어의 인코딩 방식을 모두 이해하고 지원해야합니다. 그런데 만약 다른 나라 언어의 문자 집합과 인코딩 방식이 통일되어 있다면, 다시 말해 모든 언어를 아우르는 문자 집합과 통일된 표준 인코딩 방식이 있다면 언어별로 인코딩하는 수고로움을 덜 수 있을 겁니다. 그래서 등장한 것이 유니코드(unicode)문자 집합입니다. 유니코드는 EUC-KR보다 훨씬 다양한 한글을 포함하며 대부분 나라의 문자, 특수문자, 화살표나 이모티콘까지도 코드로 표현할 수 있는 통일된 문자 집합입니다. 유니코드는 현대 문자를 표현할 때 가장 많이 사용되는 표준 문자 집합이며, 문자 인코딩 세계에서 매우 중요한 역할을 맡고 있습니다.
간혹 유니코드 글자에 부여된 값 앞에 U+D55C, U+AE00처럼 U+라는 문자열을 부이기도 하는데, 이는 십육진수로 유니코드를 표현할 때 사용하는 표기입니다.
'CS' 카테고리의 다른 글
| 혼자 공부하는 컴퓨터구조 + 운영체제 | 9장 ~ 11장 (0) | 2022.12.20 |
|---|---|
| 쉽게 배우는 운영체제 | 교착 상태 (0) | 2022.12.02 |
| 쉽게 배우는 운영체제 | 공유 자원과 임계구역 (0) | 2022.11.16 |
| 쉽게 배우는 운영체제 | 프로세스 동기화 (0) | 2022.11.13 |
| HTTP 완벽 가이드 | URL과 리소스 (0) | 2022.07.25 |



