Files & File System
컴퓨터는 정보들을 자기 디스크, 자기테이프, 광 디스크와 같은 다양한 저장매체에 저장합니다. 운영체제는 저장장치의 물리적 특성을 추상화하여 논리적 저장 단위인 파일을 정의합니다. 파일은 운영체제에 의해 물리 장치들로 맵핑되고, 일반적으로 비휘발적 성격을 지니고 있어서 전원이 끊어진 이후에도 정보들을 영구히 보존합니다.
파일은 컴퓨터 시스템의 편리한 사용을 위해 정보 저장의 일괄된 논리적 관점을 제공합니다. 일반적으로 레코드 혹은 블록 단위로 비휘발성 보조장치에 저장됩니다.
사용자의 편의를 위해 파일에 이름을 부여하고 하나의 문자열로 나타냅니다. 파일이 만들어지는 순간 그 파일은 프로세스, 사용자, 시스템으로부터 독립하게 됩니다. 파일은 다음과 같은 속성을 지닙니다.
- 이름: 사람이 읽을 수 있는 형태로 유지되는 유일한 정보
- 식별자: 파일 시스템 내에서 파일을 식별하는 고유의 번호 PK
- 타입: 여러 타입의 파일을 제공하는 시스템을 위해 필요
- 위치: 장치 내에서 파일의 위치를 가리키는 포인터
- 크기: 현재 파일의 크기
- 보호: 접근 제어 정보
- 시간, 날짜, 사용자 식별: 생성, 최근 변경, 최근 사용등에 대한 정보
모든 파일에 대한 정보는 보조 저장 장치에 상주하는 디렉터리 구조 내에 유지됩니다. 파일과 디렉터리 모두 비휘발적 성질을 가져야 하므로, 저장 장치 상에 저장되고, 필요할 때 조금씩 메모리로 가져옵니다.
파일 시스템은 디스크에 존재하는 데이터와 프로그램의 저장과, 접근할 수 있는 기법을 제공합니다. 시스템 내의 모든 파일에 대한 정보를 제공하는 계층적 디렉터리 구조이고, 파일 및 파일의 메타데이터, 디렉터리 정보등을 관리합니다.
파일 연산
운영체제가 파일을 관리하기 위해 사용하는 시스템 콜과 그것들의 조합을 파일 연산이라고 합니다.
- 파일 읽기: 파일 이름과 파일이 읽혀 들어갈 블록의 위치를 명시하는 시스템 콜을 호출. 다음 읽기가 일어날 파일 안의 위치를 기록하는 읽기 포인터를 유지해야함. 프로세서는 일반적으로 파일 읽기나 파일 쓰기 중 한가지를 하고 있기 때문에, 대부분의 시스템은 한개의 현재 파일 위치 포인터를 가집니다. 읽기, 쓰기 연산 모두 이 포인터를 이용해 공간을 절약하고 복잡성을 감소시킴.
- 파일 쓰기: 파일 이름과 기록될 정보를 명시하는 시스템콜을 호출. 시스템은 파일 내의 다음 쓰기가 일어날 위치를 가리키는 쓰기 포인터를 유지하고 있어야함.
- 파일 생성: 사용할 수 있는 공간을 찾고 파일을 할당.
- 파일 안에서 위치 재설정: 디렉터리에서 적합한 항목을 탐색하고, 현재 파일 위치를 주어진 값으로 설정.
- 파일 절단: 파일의 내용은 지우고, 속성만을 남깁니다.
- 파일 삭제: 지명된 파일을 찾고 발견한다면 파일이 차지하는 공간을 방출하고 디렉터리 항목을 삭제.
운영체제는 모든 열린 파일에 대한 정보를 갖는 열린 파일 테이블 (open file table)을 유지합니다.
시스템 콜 open()은 전형적으로 열린 파일 테이블의 항목에 대한 포인터를 리턴합니다.
Access Methods
파일에 접근하여 데이터를 읽는 방법에는 순차접근(Sequential Access), 직접 접근(Random Access), 색인 접근(Index Access)으로 나뉩니다.
1. 순차 접근

파일의 정보가 레코드 순서대로 처리됩니다. 테이프 모델에 기반을 두고 있습니다. 현재 위치에서 읽거나 쓰면 자동으로 offset이 증가하고 뒤로 돌아가기 위해서는 되감기가 필요합니다.
2. 직접 접근

특별한 순서 없이 빠르게 레코드를 읽고 쓸 수 있습니다. 디스크 모델에 기반을 두며 이는 무작위 파일 블록에 대한 임의 접근(Random Access)를 허용하기 때문입니다. LP판을 사용하는 방식과 동일합니다.
3. 색인 접근
파일에서 레코드를 찾기 위해 색인을 먼저 찾고, 대응되는 포인터를 얻습니다. 이를 통해 파일에 직접 접근해서 원하는 데이터를 얻을 수 있습니다. 따라서 크기가 큰 파일에 유용합니다.

HardDisk

- platter: 실제 데이터를 기록하는 자성을 가진 원판이다. platter는 그림과 같이 여러 개가 존재하고 앞뒤로 사용할 수 있다. 한 platter는 여러 개의 track으로 이루어져 있다.
- track: platter의 동심원을 이루는 하나의 영역이다.
- sector: 하나의 track을 여러 개로 나눈 영역을 sector라 한다. sector size는 일반적으로 512 bytes이며 주로 여러 개를 묶어서 사용한다.
- cylinder: 한 cylinder는 모든 platter에서 같은 track 위치의 집합을 말한다.
sector는 여러개로 묶어서 사용하는데 이를 블록이라고 한다. 하드 디스크는 블록 단위로 읽고 쓰기 때문에 block device라고 부르기도 한다. 하드디스크가 블록 단위로 읽고 쓰는 것을 확인할 수 있는 간단한 방법은 메모장 프로그램에서 알파벳 a만을 적고 저장해보자. a는 character로 1byte 크기를 갖는데, 실제 저장된 텍스트 파일의 속성을 확인하면 디스크에 4KB(하나의 block size) 가 할당되는 것을 확인할 수 있다.(실제 디스크 할당 크기는 운영체제마다 다르다.)
이제 운영체제가 각각의 파일에 대해 free block을 어떻게 할당하는지 알아보자.

블록을 할당하는 방법은 크게 연속할당, 연결할당, 색인할당 세가지가 존재한다.
1. Continguous Allocation
연속할당은 말그대로 연속된 블록에 파일을 할당하는 것이다. 디 렉터리에는 파일의 시작 부분의 위치와 파일의 길이에 대한 정보를 저장하면 전체를 탐색할 수 있다.
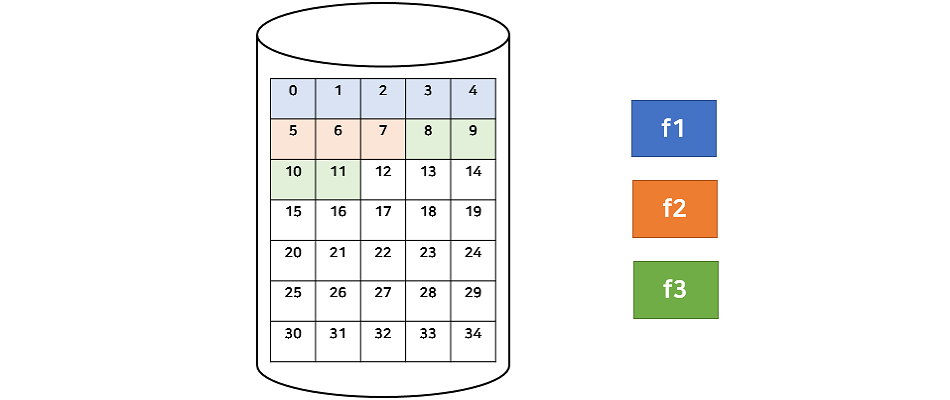
연속할당은 디스크 헤더의 이동을 최소화 할 수 있어 I/O 성능을 높인다. 또한 연속적으로 저장할 수 있으므로 한번의 탐색으로 많은 양을 전송할 수 있다. 그리고 Random Access가 가능하다. 하지만 외부 단편화가 발생하여, 파일의 크기를 키우기가 어렵다. 파일의 커질 가능성을 고려해서 미리 큰 공간을 할당한다면 내부 단편화가 발생할 수도 있다.
2. Linked Allocation
연결 할당(Linked Allocation)은, 연속적으로 할당하지 않고 빈 위치면 자유롭게 할당될 수 있다. 자료구조중 Linked List와 같은 방식으로 파일을 할당한다. 각 블록에 마지막 주소를 저장하는 포인터 공간(4bytes)가 존재하며, 여기서 다음 블록을 가리키고 있다. 마지막 블록의 포인터 공간에는 끝임을 나타내는 값이 저장되어 있다.

연결 할당을 사용해 새로운 파일을 할당할 때는 비어있는 임의의 블록을 첫 블록으로 선택하며, 만약 파일이 커지는 경우 다른 블록을 할당해서 기존의 블록과 연결만 해주면 된다. 연결할당은 위치와 상관없이 할당이 가능하므로 외부 단편화 문제가 없다.( = 디스크 낭비가 없다.)
링크드 리스트의 형태로 구현되어있기 때문에 순차접근은 가능하지만 직집 접근은 불가능하다. 또한 포인터를 저장하는 4bytes이상의 손해가 발생한다.
글을 읽다보니 Linked Allocation은 링크드 리스트의 문제점을 모두 갖는다. 예를 들면 중간에 끊어지면 이후의 모든 블록에 접근하지 못하는 낮은 신뢰성, 블록이 모두 흩어져 있으므로 디스크 헤더의 움직임이 많이 발생하는 느린 속도를 예로 들 수 있다.
위 Linked Allocation의 문제를 개선하기 위해 나온것이 같은 연결 할당 방식인 FAT(File Allocation Table)시스템이다. FAT시스템에서는 다음 블록으로 가리키는 포인터들만 모아서 하나의 테이블 FAT을 만들어 한 블록에 저장한다.

위 그림은 FAT 파일 시스템 방식으로 저장한 모습이다. 0번 블록에 저장된 FAT에는 전체 디스크의 블록번호화 각 인덱스마다 다음 블록 번호를 저장하고 있는 것을 볼 수 있다.
FAT 시스템을 사용하면 기존의 연결 할당의 문제점을 대부분 해결할 수 있다. FAT를 한번만 읽으면 직접 접근이 가능하고, FAT만 문제가 없다면 중간 블록에 문제가 생겨도 FAT를 한번만 읽으면 직접 접근이 가능하다.
FAT는 일반적으로 메모리 캐싱을 사용하여 블록 위치를 찾는데는 빠르지만 실제 디스크 헤더가 움직이는 것은 실제 블록이 흩어져 있기 때문에 여전히 느리다. 마지막으로 FAT는 매우 중요한 정보이므로 손실시 복구를 위해 이중 저장을 한다.
FAT는 각 인덱스 크기는 전체 블록의 개수를 저장할 만큼의 크기를 가지고 있어야하는데, 현재는 일반적으로 32bit 크기를 사용한다. 이를 FAT32라고 부른다.
3. Indexed Allocation
색인 할당 역시 연결 할당과 같이 데이터를 랜덤한 블록 번호에 할당하지만 할당된 블록 번호 (포인터)를 하나의 블록에 따로 저장한다. 이러한 블록을 인덱스 블록이라고 부르며 파일 하나당 인덱스 블록이 존재한다. 색인 할당은 디렉토리 정보가 다른 할당과 다른데, 시작 블록 번호를 저장하는 것이 아니라 인덱스 블록 번호를 저장한다.
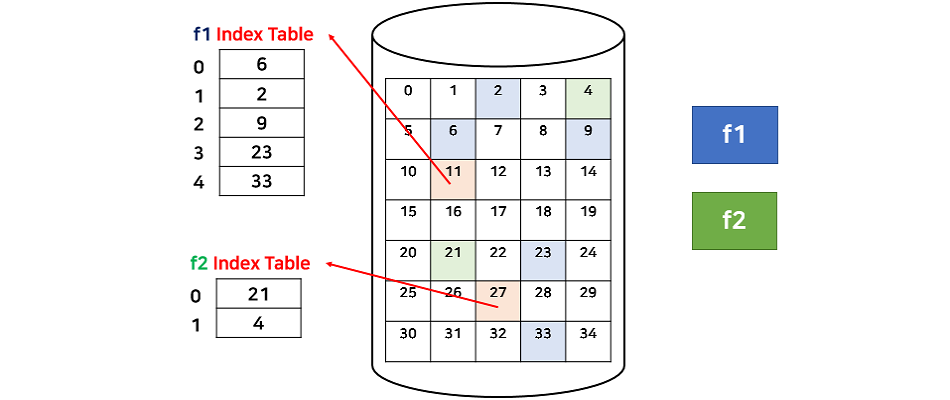
색인 할당은 인덱스 블록에 할당된 블록을 순서대로 저장하기 때문에 직접접근이 가능하다. 그리고 연속적으로 할당할 필요가 없으므로 외부 단편화 문제 또한 발생하지 않는다. 색인 할당은 Unix/Linux에서 주로 사용한다.
색인 할당의 단점은 작은 크기의 파일인 경우에도 하나의 블록을 인덱스 블록으로 사용하기 때문에 저장 공간이 손실된다. 그리고 하나의 인덱스 블록을 가지고는 크기가 큰 파일을 저장할 수 없다.
예를 들어, 하나의 블록 크기가 512 bytes인 블록은 최대 저장할 수 있는 블록 인덱스 개수는 512 / 4 bytes(포인터 크기) = 128개이다. 즉 파일의 최대 크기는 128 512bytes = 64KB로 아주 작은 크기이다. 블록 크기가 1KB이라 하더라도 최대 인덱스 개수는 256개(1000/4)이고 최대 파일의 크기는 256KB(2561KB)이다.
이를 해결하기 위한 여러 가지 방법이 있다.
- Linked: 이 방식은 인덱스 블록을 여러 개 만들어 연결 할당을 하는 것과 같다. 즉, 각 인덱스 블록의 마지막은 다음 인덱스 블록을 가리키는 포인터가 저장되어 있다.

- Multilevel index: 이 방식은 계층을 두는 방법으로 하나의 인덱스 블록의 모든 포인터가 다른 인덱스 블록을 가리킨다. 만약 이것으로 부족하면 계층을 더 만들어 간다.

- Combined: 이 방식은 Linked와 Multilevel index를 합친 방법으로 한 인덱스 블록의 포인터들은 데이터 블록과 또 다른 인덱스 블록 둘 다 가리킬 수 있다.(리눅스는 combined 방식을 사용한다.)
교수님 Talk.
- 데이터베이스와 파일시스템의 차이. OS는 파일 시스템을 제공해준다. 파일의 데이터의 모습은 OS에서는 상관하지않는다. OS는 섬세한 access control은 안됨. DB는 레코드 필드 단위로 접근. 섬세한 접근 control, 접근 protection
- unix는 파일을 a stream of byte로 취급 (바이트들의 모음)
- unix file system의 첫번째 블록 boot block -> 부팅작업, 그다음 읽는게 super block
- super block은 파일시스템에 대한 일반적 정보를 보관. 부팅이 된 후 메인메모리로 읽힘.
- 2,3,4, .... M-1 iNode list, M ~ N - 1 -> Data Block
- 하나의 파일이 생성되기 위해 하나의 INode(파일에 관련된 여러가지 속성 값)가 필요. 프로세스가 생성되기 위해선 PCB가 필요.
- INode는 하드디스크 블록내에 쪼개져서 들어가있음.
- unix에서는 directory도 파일로 취급한다.
- file directory structure 발전. single level directory -> two level directory -> tree structured directory -> acyclic graph directory
'CS' 카테고리의 다른 글
| 쉽게 배우는 운영체제 | ch7. 물리 메모리 관리 (0) | 2022.06.18 |
|---|---|
| 쉽게 배우는 운영체제 | ch8. 가상 메모리 기초 (0) | 2022.06.18 |
| Ch2. Operating System Overview (3/3) (0) | 2022.06.07 |
| Ch2. Operating System Overview (2/3) (0) | 2022.06.05 |
| Ch2. Operating System Overview (1/3) (0) | 2022.06.04 |



